
FacebookがHBaseを大規模リアルタイム処理に利用している理由(後編)
Facebookは大規模なデータ処理の基盤としてHBaseを利用しています。なぜFacebookはHBaseを用いているのか、どのように利用しているのでしょうか? 7月1日に都内で行われた勉強会で、Facebookのソフトウェアエンジニアであるジョナサン・グレイ(Jonathan Gray)氏による解説が行われました。

この記事は、「FacebookがHBaseを大規模リアルタイム処理に利用している理由(前編)」の続きです。
事例1 Titan(Facebookメッセージ)
HBaseがFacebookでどのようなアプリケ-ションで使われているのかを紹介しよう。
Facebookの新メッセージ機能。

これはFacebook史上、最大規模の開発作業で、15人のエンジニアが1年以上開発を行ったもの。しかも初日から途方もない規模で展開されるサービスだ。

メッセージ機能のチャレンジは、高い書き込み性能を実現しなければならなかったことと、データが減ることはないので、容易にスケールアウトできる大規模なクラスタの実現だった。

これが典型的なHBaseのクラスタ構成。セルと呼んでいる。多くのセルを稼働させているが、セルはだいたい100台のサーバがある。1ラックあたり20サーバで5ラック以上。

事例2 Puma(Facebookインサイト)
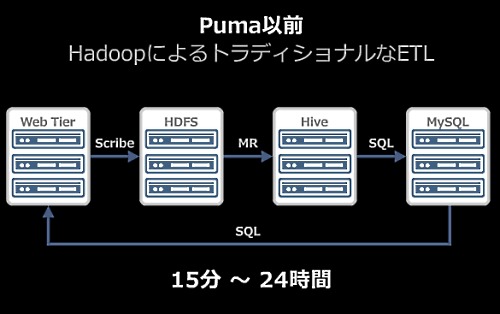
Puma以前は、トラディショナルなETL処理をHadoopで構築していた。
数千台のWebサーバ群からScribeでログを集約してHDFSに保存し、MapReduce処理をしてそれをMySQLに保存していた。この処理には、おおむね15分から24時間かかっていた。
リアルタイムなETLシステムであるPumaでは、Webサーバ群からScribeでログをHDFSに集約すると、それを前述のHDFSのAppend機能を使って書き(つまり書き込み中にSyncするとそこまでの内容がほかのクライアントから読み込めるようになり、続きが追記されていく)、それをPTailでPumaへ送り、HTableでHBaseへ書き込んでいる。この処理は、10秒から30秒である。
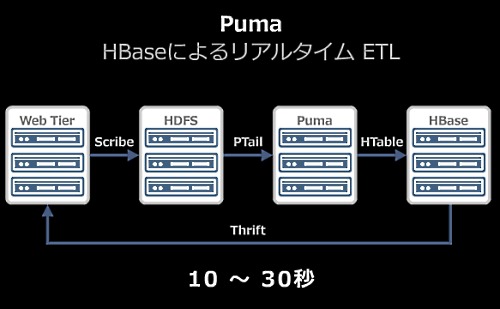
Pumaにより、リアルタイムなデータのパイプラインでデータを集約、処理している。

リアルタイムにアクセス分析できる。しかも数十億のURLを扱い、毎秒100万件以上のカウントアップがあるようなスループットを対象にしている。

事例3 ODS(Facebook内部メトリックス)
Facebookの運用データのためのデータストアにHBaseを利用する。

FacebookがHBaseを利用している最大の理由はコストが安く済むところだ。MySQLをスケールさせることには成功しているが、コストがかかる。
HBaseはシーケンシャルなディスク書き込みだけを行うため、安いハードウェアで高い性能を安価に実現できる。

