




はじめに
こんにちは、データシステム部データ基盤ブロックSREの纐纈です。
本記事では、過去に遡ってBigQueryのデータを参照する方法(以下、タイムトラベルと呼びます)をご紹介します。また、この機能はBigQueryが提供している、変更または削除されたデータにアクセスするタイムトラベルとは異なることをご了承ください。
開発背景
この機能は過去データを日次スナップショットより細かい粒度で見たい、また障害対応時に障害発生前などピンポイントで時間指定して参照したいという要望を受け、開発することになりました。
さらに、BigQueryからこの機能を作るのに役立ちそうなテーブル関数という機能がリリースされたのもきっかけとなりました。
テーブル関数とは、事前にパラメータを使って定義したクエリをエイリアスのようにテーブルとして保存して、そのテーブルに対して関数を実行するかのようにクエリを書ける機能です。例えば、以下のようにテーブル関数を定義するとします。
CREATE TABLE FUNCTIONS `some_dataset.foo_records_by_name`(name_param STRING) AS SELECT * FROM `some_dataset.foo` WHERE name = name_param
その上で、このようなクエリを実行するとします。
SELECT * FROM `foo_records_by_name`('bar')
すると、事前に定義したテーブル関数がパラメータを代入して、結果としてこちらのクエリが実行されます。
SELECT * FROM `some_dataset.foo` WHERE name = 'bar'
短いクエリだと受けられる恩恵が少ないですが、長いクエリに対しては重宝される機能かと思います。
タイムトラベルの機能
SELECT * FROM `<table ID>`('2021-01-01')
テーブル関数を使用して上のようにクエリを打つと、指定した日時の状態のデータを参照できます。
実際に実行されているクエリは、こちらです。クエリ内のpast_timeはTIMESTAMP型で、テーブル関数から渡されるパラメータです。
WITH snapshot_validation AS ( SELECT '<base_table>' AS table_id, MAX(creation_time) AS snapshot_validation_time, FROM `<snapshot_dataset>.INFORMATION_SCHEMA.TABLES` WHERE REGEXP_CONTAINS( table_name, CONCAT('<base_table>','_',FORMAT_TIMESTAMP("%Y%m%d", TIMESTAMP_SUB(past_time, INTERVAL 1 DAY), "Asia/Tokyo") ))), streaming_data_validation AS ( SELECT table_id, min_bigquery_insert_time AS streaming_validation_time FROM `<changetracking validation table ID>` WHERE dataset_id = '<changetracking_dataset>' AND table_id = '<changetracking_table>'), validation AS ( SELECT a.table_id, snapshot_validation_time, streaming_validation_time FROM snapshot_validation AS a INNER JOIN streaming_data_validation AS b ON a.table_id = b.table_id), nearest_snapshot AS ( SELECT *, CONCAT(${join(",", primary_key)}) AS primary_key FROM `<snapshot_dataset>.<base_table>_*` AS snapshot_table WHERE _TABLE_SUFFIX IN (FORMAT_TIMESTAMP("%Y%m%d", TIMESTAMP_SUB(past_time, INTERVAL 1 DAY), "Asia/Tokyo"))), changetracking_for_two_days_until_specified_time AS ( SELECT * FROM ( SELECT *, id AS primary_key FROM `changetracking_dataset.changetracking_table` WHERE bigquery_insert_time BETWEEN TIMESTAMP_SUB(past_time, INTERVAL 2 DAY) AND past_time ) AS changetracking ), changetracking_latest_version_key_group AS ( SELECT primary_key, MAX(CAST(changetrack_ver AS int64)) AS changetrack_ver, MAX(changetrack_start_time) AS changetrack_start_time FROM changetracking_for_two_days_until_specified_time GROUP BY primary_key ), changetracking_latest_version AS ( SELECT a.* FROM changetracking_for_two_days_until_specified_time AS a INNER JOIN changetracking_latest_version_key_group AS b ON a.primary_key = b.primary_key AND a.changetrack_ver = b.changetrack_ver ), changetracking_without_duplication AS ( SELECT * FROM ( SELECT *, ROW_NUMBER() OVER (PARTITION BY primary_key ORDER BY primary_key) AS row_number FROM changetracking_latest_version) WHERE row_number = 1 ), nearest_snapshot_except_what_changetracking_included AS ( SELECT * FROM nearest_snapshot WHERE primary_key NOT IN ( SELECT primary_key FROM streaming_diff ) ) SELECT ... -- columns in the base table (cannot use *) to align with changetracking FROM nearest_snapshot_except_what_changetracking_included UNION ALL SELECT ... -- columns in the base table (cannot use *) since changetracking_without_duplication has more columns FROM changetracking_without_duplication WHERE changetrack_type != 'D' AND IF (snapshot_validation_time IS NOT NULL, TRUE, ERROR( CONCAT("Cannot time-travel since snapshot data does not exist for the specified time." ) )) AND IF (past_time > streaming_validation_time, TRUE, ERROR( CONCAT("Cannot time-travel since recording changetracking had not started at the time. check nearest daily snapshot directly. Specify time after: ", streaming_validation_time)))
このクエリの中では、パタメータに渡された日時をもとに以下の内容を実行しています。
- 指定された日のテーブルコピーがあるかチェック
- 差分データがあるかチェック
- 日次で取っているテーブルのコピーからデータを取得する
- テーブルコピーに記録されている最終時刻と指定した時間までの差分データを変更履歴ログから摘出する
- 組み合わせて指定された時刻のテーブルの状態を再現する
そして、そのテーブルに対して元々のSELECT文のクエリを実行するという仕組みになっています。

使われているテーブルについて、簡単に説明します。
base_table:元となるテーブルで、このテーブルの過去データを見ることがタイムトラベル機能の目的です。
daily_snapshot:base_tableの日次テーブルコピー。データ基盤を構築するために、日次バッチによってBigQueryにテーブルデータを転送しており、その際にその日時点でのテーブルのコピーを取っています。データ転送用の日次バッチは日本時間0時に動かしていますが、必ずしも0時時点のデータとは限りません。テーブル定義はbase_tableと全く同じです。
change_tracking:base_tableの変更追跡ログ。これはSQL ServerのChange trackingという機能によって保存されているテーブルです。データベース上のテーブルに対してinsert, update, deleteの変更が入る度に、変更に関する情報が記録されています。
changetrackingのテーブルは、base_tableのカラムと変更追跡のカラム、また転送バッチが実行された時刻のカラムによって定義されています。この機能に使われている追加のカラムのみ、説明します。
| カラム名 | 型 | 説明 |
|---|---|---|
| changetrack_ver | INTEGER | 変更された行のバージョン番号(初めて変更された場合は1、max(changetrack_ver)で最新の変更情報が取得できる) |
| changetrack_type | STRING | 変更追跡のタイプ(I - insert, U - update, D - delete) |
| changetrack_start_time | TIMESTAMP | 変更追跡の開始日時 |
| bigquery_insert_time | TIMESTAMP | 転送バッチによってBigQueryに追加された日時 |
詳しい仕組みなどは、公式ドキュメントをご参照ください。
弊チームでは、リアルタイムデータ基盤を構築する際、Change trackingの機能を使いました。そのため既にBigQuery上に転送される仕組みが構築されており、今回の機能に必要な条件も満たしていたため、こちらを利用することにしました。リアルタイムデータ基盤について詳しく知りたい場合は、こちらをご参照ください。
SQL Serverだけでも変更履歴を取得する方法はいくつかあるので、Change trackingでなくCDC(Change Data Capture)でも実装可能です。Change Trackingからは変更後のレコードの値が取得できるため、ベースとなるテーブルコピーに対してChange Trackingの変更後の値を追加するという方式を取っています。しかし、CDCのように変更前の値も取れるものを採用するのであれば、ベースから遡ることもできます。
では、ここからは実際にクエリの中身を解説しつつどう実装したのか見ていきます。
実施したこと
データ基盤にあるテーブルの日次コピーを取るようにする
タイムトラベルにあたって過去の状態のデータを再現するには、ベースとなる日次テーブルコピーが必要です。
元々分析チームの要望などによって、いくつかのテーブルは過去データが参照できるよう日次データ転送時にテーブルのコピーを取って保存していました。そのため、その機能を元にタイムトラベル機能を使えるよう日次コピーを取るテーブルを拡張しました。
change trackingに関しては既に転送設定がされているので、この時点でタイムトラベルに必要なデータが揃います。

クエリの作成
テーブルコピーと変更ログの準備ができたので、タイムトラベル用のクエリを生成していきます。分割しつつ、順を追って説明します。
まず、テーブル関数を定義します。任意の指定した時刻をパラメータとして受け取るテーブル関数を作るため、以下のような形式となります。SELECT以降にこのパラメータを使いつつ、取得するデータを決めていきます。
CREATE OR REPLACE TABLE FUNCTION `project.dataset.table`(past_time TIMESTAMP) AS SELECT ...
ここからは、SELECT文以降の説明に移ります。前述した通り、今回のタイムトラベル機能はテーブルコピーと変更ログからデータを取得し、それを組み合わせて結果を返します。フローチャートを描くと、以下のようになります。
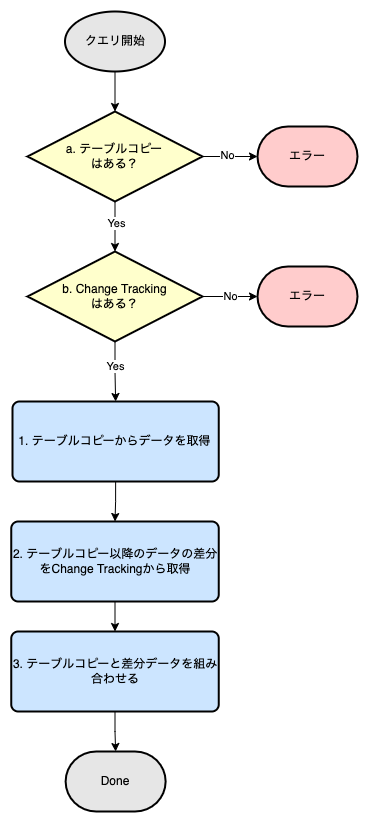
フロートチャートに沿って、順に説明します。
バリデーション (a, b)
今回のタイムトラベルの機能はどこまでも過去に遡れるというわけではありません。ベースとなるテーブルコピーと変更ログの両方がないと過去テーブルの再現はできないので、もしどちらかの機能が運用開始される前の時点にタイムトラベルしようとした場合は、警告を出す必要があります。
a. テーブルコピーの存在チェック
まず、テーブルコピーを取得する前に、指定された日時の1日前のテーブルコピーが存在するか確認します。
なぜ1日前なのかというと、指定された日の当日だとスナップショットが作られる前の時刻が指定された時に、スナップショットの作成時刻の方が指定された時刻より新しいという状態になってしまうためです。転送バッチには他の処理もあるため0時ちょうどに始まるわけではなく、スナップショットが作成される時刻も0時ではありません。そのためバッファーを持たせてあります。
該当するテーブルコピーがあるかはINFORMATION_SCHEMAを参照すると確認できます。INFORMATION.TABLESには任意のデータセットに含まれるテーブルのメタ情報が入ってます。そのため、<base_table_name>_YYYYmmddのフォーマットで指定した日時より1日前のテーブル名が存在しているかを確認します。
past_timeを指定した時刻のパラメータとして、その1日前の日付をYYYYmmdd形式で表すと以下のようになります。
FORMAT_TIMESTAMP("%Y%m%d", TIMESTAMP_SUB(past_time, INTERVAL 1 DAY), "Asia/Tokyo"))
その上で、バリデーションのクエリはERROR関数を使って、以下のように行えます。ERROR関数については、公式ドキュメントをご参照ください。
-- past_time: テーブル関数から渡されるパラメータ、TIMESTAMP型 WITH snapshot_validation AS ( SELECT '<base_table_name>' AS table_id, MAX(creation_time) AS snapshot_validation_time, FROM `<snapshot_dataset>.INFORMATION_SCHEMA.TABLES` WHERE REGEXP_CONTAINS( table_name, CONCAT('<base_table_name>','_', FORMAT_TIMESTAMP("%Y%m%d", TIMESTAMP_SUB(past_time, INTERVAL 1 DAY), "Asia/Tokyo")) ))) SELECT ... FROM snapshot_validation WHERE IF (snapshot_validation_time IS NOT NULL, TRUE, ERROR( CONCAT("Cannot time-travel since snapshot data does not exist for the specified time." ) ))
b. Change Trackingの存在チェック
指定された時刻からテーブルコピーまでの差分データが存在しているかを調べるためには、変更ログを保存しているテーブルをスキャンしなければなりません。変更ログのテーブルはデータ量も膨大なので、毎度スキャンをしていたら使い勝手が悪くなります。
そこで新たにこのバリデーション用のテーブルを作り、キャッシュのように利用することにしました。新たにバッチ処理を追加して、テーブルごとの連携が開始された時期をテーブルが追加され次第書き込むようにします。バッチで動かすクエリは以下になります。
SELECT database_name as dataset_id, table_name as table_id, MIN(bigquery_insert_time) AS min_bigquery_insert_time FROM `<change tracking table>` WHERE database_name IS NOT NULL AND table_name IS NOT NULL GROUP BY dataset_id, table_id
これで変更ログが存在しているかを確認するときは、このテーブルを見ることで容易に参照できるようになりました。よって、シンプルかつ高速にバリデーションを行えるようになりました。クエリとしては、以下のようになります。
-- past_time: テーブル関数から渡されるパラメータ、TIMESTAMP型 WITH changetracking_data_validation AS ( SELECT table_id, min_bigquery_insert_time AS changetracking_validation_time FROM `<validation table ID for changetracking>` WHERE dataset_id = '<dataset_name>' AND table_id = '<base_table_name>') SELECT ... FROM changetracking_data_validation WHERE IF (past_time > changetracking_validation_time, TRUE, ERROR( CONCAT("Cannot time-travel since recording changetracking had not started at the time. Specify time after: ", changetracking_validation_time, "Or check nearest daily snapshot directly.")))
データの取得 (1, 2, 3)
1. テーブルコピーの取得
まず、テーブルコピーからデータを持ってくるクエリは以下のようになります。テーブルコピーの名前はTable_20220224のような形式で保存しているので、_TABLE_SUFFIXを使って対象のテーブルコピーを見つけます。バリデーションの箇所で述べた通り、パラメータで指定された時刻より1日前のテーブルコピーを取得します。
-- past_time: テーブル関数から渡されるパラメータ、TIMESTAMP型 SELECT * FROM `snapshot_dataset.base_table_*` AS snapshot_table WHERE _TABLE_SUFFIX IN (FORMAT_TIMESTAMP("%Y%m%d", TIMESTAMP_SUB(past_time, INTERVAL 1 DAY), "Asia/Tokyo"))
2. Change Trackingの取得
次に、テーブルコピーからパラメータで指定された日時までの差分データを取得します。
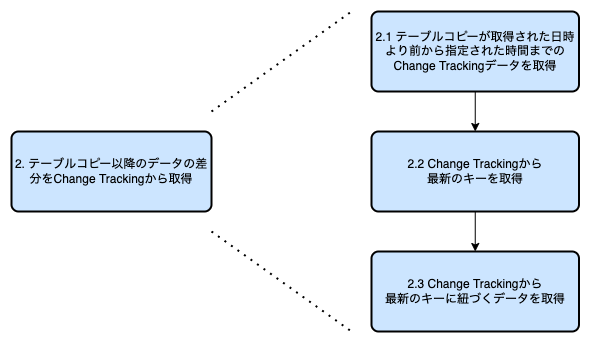
ChangeTrackingから差分データを取得するのは、少し複雑なのでさらに分割して説明します。
2.1. テーブルコピーが取得された日時より前から指定された時間までのChange Trackingデータを取得
差分データを取得する際に、考慮しないといけないことはテーブルコピーがいつ取得されたかということです。とはいえ、テーブルコピーが取られる時刻は固定ではなく、バッチの遅延や前処理にかかった時間によって変わります。
そのため、前日のテーブルコピーがいつ作成されていても対応できるよう、指定された日時から2日間分の変更ログを取得します。その後、テーブルコピーと重複した部分を組み合わせる際に排除すると、2つのデータに重複がなくなります。クエリにすると、以下のようになります。
-- past_time: テーブル関数から渡されるパラメータ、TIMESTAMP型 SELECT * FROM `changetracking_dataset.changetracking_table` WHERE bigquery_insert_time BETWEEN TIMESTAMP_SUB(past_time, INTERVAL 2 DAY) AND past_time
2.2. Change Trackingから最新のキーを取得
Change Trackingには変更後の値が主キーと紐づけられて保存されています。複数回の更新が走った時に、どのデータが最新のバージョンかを確認するためには、changetrack_verというカラムが使えます。
削除されていた場合を除いて、changetrack_verが指定された時点で最大のものが、その時点でのデータとなっています。削除されていた場合は、そのデータを排除しなければいけませんが、これは3のセクションで後述します。
まず、主キーに応じてそれぞれchangetrack_verの最大値を取得します。
WITH -- step 2.1 changetracking_for_two_days_until_specified_time AS ( SELECT * FROM ( SELECT *, id AS primary_key FROM `changetracking_dataset.changetracking_table` WHERE bigquery_insert_time BETWEEN TIMESTAMP_SUB(past_time, INTERVAL 2 DAY) AND past_time ) AS changetracking ) SELECT primary_key, MAX(CAST(changetrack_ver AS int64)) AS changetrack_ver, MAX(changetrack_start_time) AS changetrack_start_time FROM changetracking_for_two_days_until_specified_time GROUP BY primary_key
2.3 Change Trackingから最新のキーに紐づくデータを取得
次に、前のステップで取得した主キーとchangetrack_verを使って、変更ログから差分データを取り出します。
WITH -- step 2.1 changetracking_for_two_days_until_specified_time AS ( SELECT * FROM ( SELECT *, id AS primary_key FROM `changetracking_dataset.changetracking_table` WHERE bigquery_insert_time BETWEEN TIMESTAMP_SUB(past_time, INTERVAL 2 DAY) AND past_time ) AS changetracking ), -- step 2.2 changetracking_latest_version_key_group AS ( SELECT primary_key, MAX(CAST(changetrack_ver AS int64)) AS changetrack_ver, MAX(changetrack_start_time) AS changetrack_start_time FROM changetracking_for_two_days_until_specified_time GROUP BY primary_key ) SELECT a.* FROM changetracking_for_two_days_until_specified_time AS a INNER JOIN changetracking_latest_version_key_group AS b ON a.primary_key = b.primary_key AND a.changetrack_ver = b.changetrack_ver )
これで差分データが取得できたので、次にテーブルコピーとの組み合わせに移ります。
3. テーブルコピーと差分データを組み合わせる
2の工程までで、テーブルコピーのデータと差分データは取得できました。最後にこの2つのデータを組み合わせていきますが、いくつかまだ手を加える必要があるので、また細かくして説明します。

3.1. テーブルコピーからChange Trackingに含まれているデータを削除
現時点では、変更ログとテーブルコピーのデータには重複している部分があり、UNIONする前に除外する必要があります。これは、テーブルコピーのデータから変更ログに存在しているデータを除外することで対応できます。
SELECT * FROM nearest_snapshot -- step 1 WHERE primary_key NOT IN ( SELECT primary_key FROM changetracking_latest_version )
3.2. 差分データからDELETE用のデータを削除
また、変更ログをUNIONする際に変更ログのタイプが'削除'でないもののみを抽出する必要があります。なぜなら、そのデータは指定された時間では削除されているべきデータだからです。ここで、changetrack_typeのカラムを使います。changetrack_type = 'D'が削除の変更がされたというログなので、changetrack_ver != 'D'であるデータのみを差分データとして利用します。クエリは以下のようになります。
SELECT * FROM changetracking_latest_version -- step 2.3 WHERE changetrack_type != 'D'
3.3. テーブルコピーと差分データをUNIONする
以上をまとめて、最後にテーブルコピーのデータとChange Trackingから取得した差分データをUNIONすると、SELECT文が完成します。
-- past_time: テーブル関数から渡されるパラメータ、TIMESTAMP型 WITH -- step 1 nearest_snapshot AS ( SELECT *, CONCAT(${join(",", primary_key)}) AS primary_key FROM `${project_snapshot}.${dataset_snapshot}.${table_base}_*` AS snapshot_table WHERE _TABLE_SUFFIX IN (FORMAT_TIMESTAMP("%Y%m%d", TIMESTAMP_SUB(past_time, INTERVAL 1 DAY), "Asia/Tokyo"))), -- step 2.1 changetracking_for_two_days_until_specified_time AS ( SELECT * FROM ( SELECT *, id AS primary_key FROM `changetracking_dataset.changetracking_table` WHERE bigquery_insert_time BETWEEN TIMESTAMP_SUB(past_time, INTERVAL 2 DAY) AND past_time ) AS changetracking ), -- step 2.2 changetracking_latest_version_key_group AS ( SELECT primary_key, MAX(CAST(changetrack_ver AS int64)) AS changetrack_ver, MAX(changetrack_start_time) AS changetrack_start_time FROM changetracking_for_two_days_until_specified_time GROUP BY primary_key ), -- step 2.3 changetracking_latest_version AS ( SELECT a.* FROM changetracking_for_two_days_until_specified_time AS a INNER JOIN changetracking_latest_version_key_group AS b ON a.primary_key = b.primary_key AND a.changetrack_ver = b.changetrack_ver ), -- step 3.1 nearest_snapshot_except_what_changetracking_included AS ( SELECT * FROM nearest_snapshot WHERE primary_key NOT IN ( SELECT primary_key FROM changetracking_latest_version ) ) SELECT ... -- columns in the base table (cannot use *) to align with changetracking FROM nearest_snapshot_except_what_changetracking_included UNION ALL SELECT ... -- columns in the base table (cannot use *) since changetracking_without_duplication has more columns FROM changetracking_latest_version WHERE changetrack_type != 'D' -- step 3.2
最後に、バリデーションを組み合わせて、最終的なテーブル関数の完成です。
CREATE OR REPLACE TABLE FUNCTION `time_travel_dataset.some_table`(past_time TIMESTAMP) AS WITH -- step a snapshot_validation AS ( SELECT '<base_table>' AS table_id, MAX(creation_time) AS snapshot_validation_time, FROM `<snapshot_dataset>.INFORMATION_SCHEMA.TABLES` WHERE REGEXP_CONTAINS( table_name, CONCAT('<base_table>','_',FORMAT_TIMESTAMP("%Y%m%d", TIMESTAMP_SUB(past_time, INTERVAL 1 DAY), "Asia/Tokyo") ))), -- step b streaming_data_validation AS ( SELECT table_id, min_bigquery_insert_time AS streaming_validation_time FROM `<changetracking validation table ID>` WHERE dataset_id = '<changetracking_dataset>' AND table_id = '<changetracking_table>'), validation AS ( SELECT a.table_id, snapshot_validation_time, streaming_validation_time FROM snapshot_validation AS a INNER JOIN streaming_data_validation AS b ON a.table_id = b.table_id), -- step 1 nearest_snapshot AS ( SELECT *, CONCAT(${join(",", primary_key)}) AS primary_key FROM `${project_snapshot}.${dataset_snapshot}.${table_base}_*` AS snapshot_table WHERE _TABLE_SUFFIX IN (FORMAT_TIMESTAMP("%Y%m%d", TIMESTAMP_SUB(past_time, INTERVAL 1 DAY), "Asia/Tokyo"))), -- step 2.1 changetracking_for_two_days_until_specified_time AS ( SELECT * FROM ( SELECT *, id AS primary_key FROM `changetracking_dataset.changetracking_table` WHERE bigquery_insert_time BETWEEN TIMESTAMP_SUB(past_time, INTERVAL 2 DAY) AND past_time ) AS changetracking ), -- step 2.2 changetracking_latest_version_key_group AS ( SELECT primary_key, MAX(CAST(changetrack_ver AS int64)) AS changetrack_ver, MAX(changetrack_start_time) AS changetrack_start_time FROM changetracking_for_two_days_until_specified_time GROUP BY primary_key ), -- step 2.3 changetracking_latest_version AS ( SELECT a.* FROM changetracking_for_two_days_until_specified_time AS a INNER JOIN changetracking_latest_version_key_group AS b ON a.primary_key = b.primary_key AND a.changetrack_ver = b.changetrack_ver ), -- step 3 nearest_snapshot_except_what_changetracking_included AS ( SELECT * FROM nearest_snapshot WHERE primary_key NOT IN ( SELECT primary_key FROM changetracking_latest_version ) ) SELECT ... -- columns in the base table (cannot use *) to align with changetracking FROM nearest_snapshot_except_what_changetracking_included UNION ALL SELECT ... -- columns in the base table (cannot use *) since changetracking_without_duplication has more columns FROM changetracking_without_duplication WHERE changetrack_type != 'D' AND IF (snapshot_validation_time IS NOT NULL, TRUE, ERROR( CONCAT("Cannot time-travel since snapshot data does not exist for the specified time." ) )) AND IF (past_time > streaming_validation_time, TRUE, ERROR( CONCAT("Cannot time-travel since recording changetracking had not started at the time. check nearest daily snapshot directly. Specify time after: ", streaming_validation_time)))
Terraformでの管理
Terraformでこの機能を管理するにあたって、上のクエリをテンプレート化してリアルタイム連携されているテーブルの全てに対して適応しました。テンプレート化する際に気をつけることとしては、プライマリーキーとカラムはテーブルによって異なるので、そこをケアする必要があります。弊チームの基盤ではテーブルごとのカラムやプライマリーキーの情報は自動スクリプトで取得されているので、そちらを使いました。
また、テーブル関数の機能は比較的新しく、タイムトラベルの機能を実装した直後にはTerraformに実装されていませんでした。当初はBiqQuery_jobを一時的に使って対応していましたが、現在ではテーブル関数も対応しているのでこちらに切り替えました。
注意点
タイムトラベルのクエリを作る際にいくつか気をつけなければならないポイントがあったので、注意点として紹介します。
ストレージ料金とクエリ料金のバランス
この機能は日次のテーブルコピーと変更履歴ログの保存が必須です。ストレージ料金がかかることは念頭に置いた上で、クエリの実行によるスキャン量も多くなることを忘れてはいけません。 多くの変更が走るようなテーブルでは、変更ログが膨大になり、クエリ料金が大きくなります。またストレージ料金の増大を恐れてテーブルコピーの頻度を下げると、ストレージ料金は節約できるかもしれませんが、クエリのスキャン量つまりクエリ料金が増えパフォーマンスは落ちます。
スナップショット名を動的に取ってはいけない
スナップショットを取る際、以下のようなクエリをご紹介しましたがこれはテーブルコピーを日次で取ることを前提としています。
SELECT * FROM `snapshot_dataset.base_table_*` AS snapshot_table WHERE _TABLE_SUFFIX IN (FORMAT_TIMESTAMP("%Y%m%d", past_time, "Asia/Tokyo"))
こちらは当初の案から修正が入っており、以前は日次コピーのストレージ料金を懸念して古いコピーを後々間引けるよう、以下のような形で動的にテーブル名を取得しようとしていました。
SELECT MAX(creation_time) AS nearest_snapshot FROM `snapshot_dataset.INFORMATION_SCHEMA.TABLES` WHERE REGEXP_CONTAINS( table_name, r"base_table_(?:19|20)[0-9]{2}(0?[1-9]|1[0-2])(0?[1-9]|[12][0-9]|3[01])" ) -- regexp for yyyymmdd AND creation_time <= past_time )
しかし、この方法だとスキャン前にパーティションが効かないため、クエリが非常に重くなるという問題が起きました。そのため、テーブルコピーの間引きは保留にし、日次ベースで取得するようになっています。
Dataflowのリトライでデータの重複が起きる
これは運用し始めてから、判明したことです。差分データの取得時にデータの重複が発生し、原因を調べたところ、Dataflowのリトライが起因していました。
リアルタイム連携の記事でも紹介した通り、データの転送バッチにはDataflowを使っています。Change Trackingデータの転送がうまくいかず、リトライをかけるとデータが重複して保存されてしまうことがあります。データ転送にDataflowを使っている場合は、以下のようなクエリを追加すると重複を排除できます。
SELECT *, ROW_NUMBER() OVER (PARTITION BY primary_key ORDER BY primary_key) AS row_number FROM changetracking_latest_version) WHERE row_number = 1
まとめ
今回BigQueryのテーブル関数という機能を使って、過去のデータの状態のテーブルを再現し、簡単にクエリを実行する機能を作りました。現在まだ試験運用中ではありますが、ある程度使ってもらったチームからは好評を頂いています。開発した自分としてもより多くの人に使ってもらえる機能になればと思っています。また、開発当初は想定していなかった、データベースの断面が揃えられるという副次的なメリットもあるという発見もありました。この記事が同じような問題を抱えている開発者の方の助けになれば幸いです。
最後に、ZOZOでは利用者にとって使いやすいデータ基盤を整備していく仲間を募集しています。ご興味のある方は、以下のリンクからご応募ください。