ラーメン二郎分類器 : ABEJA Platformを使ってサービス公開するぞ
ラーメン二郎分類器

引用 : ラーメン二郎 三田本店 (らーめんじろう) - 三田/ラーメン | 食べログ
皆さん、ラーメン二郎は好きですか? 好きですよね? 僕は大学の目の前にラーメン二郎があったので足繁く通っていました。しかし、ラーメン二郎初心者にとっては、麺の画像を見て、それが「ラーメン二郎」なのか「長崎ちゃんぽん」なのかが見分けが付きづらいと思います。よってDeepLearningを用いて、それらの分類を自動化する仕組みをABEJA Platformを使って実装する方法について記載します。データのcrawlingなどの実装は必要ですが、学習に関してはtemplateという機能を利用するとノンプログラミングでもモデル作成が可能なので、以下の作業時間はおおよそ10分で完了できます。
既にABEJA Platform、ABEJA Platform Annotationについては記事にしているので、以下のリンクも参考にしてください。
必要なもの
- python
- version 3.6.6 (versionはこれに限定されず、実行可能)
- 「ラーメン二郎」と「長崎ちゃんぽん」の麺が写っている写真、学習データ
- icrawlerを利用してABEJA PlatformのDatalakeに結果を格納
- ABEJA Platform
- ABEJA Platformのアカウントを必要とします。
- ご利用されたい方は下記の問い合わせよりお願いいたします。
- https://abejainc.com/platform/ja/contact/
- ABEJA Platform SDK
- ラーメン二郎への愛情
- 愛情があると良し。ただし、必須ではない
手順
- ABEJA Platformのjupyter notebookを利用する
- icrawlerで画像を保存する
- 学習データのメタ情報をjsonとして作成
- ABEJA Platform Datalakeへchannelを作成
- ABEJA Platform Datalakeへ画像を登録
- ABEJA Platform Datasetの作成、学習データをimportする
- ABEJA PlatformのTemplateを用いて学習、Deployする
手順の図解
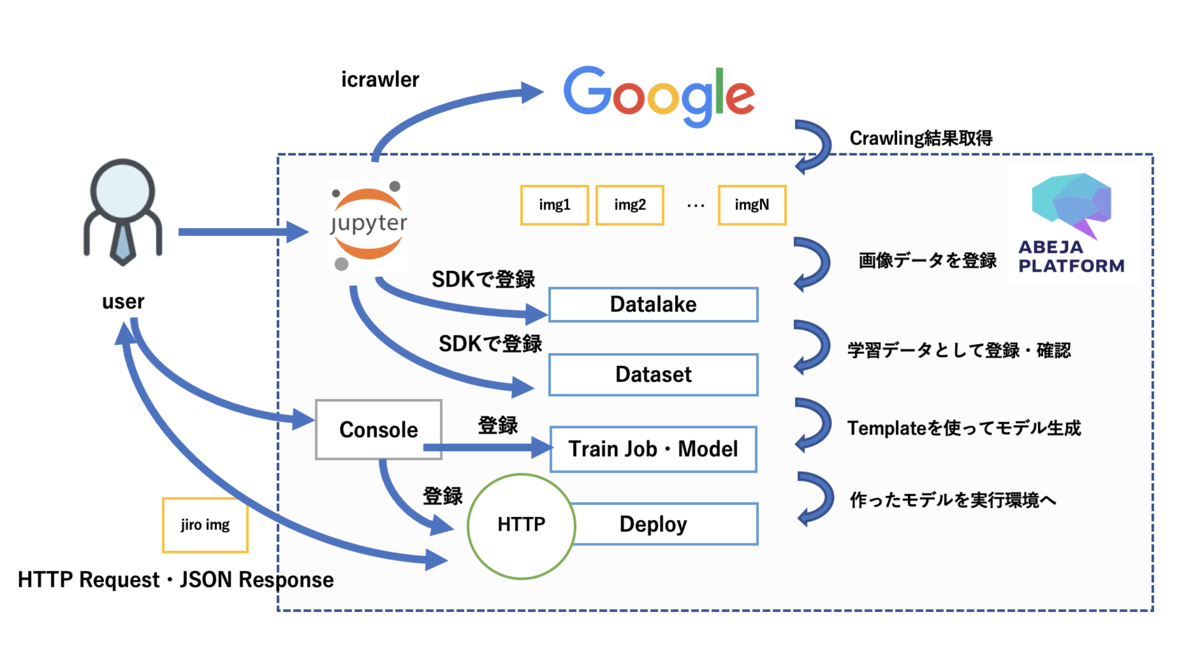
ラーメン二郎分類器をつくる
ABEJA Platformのjupyter notebookを利用する
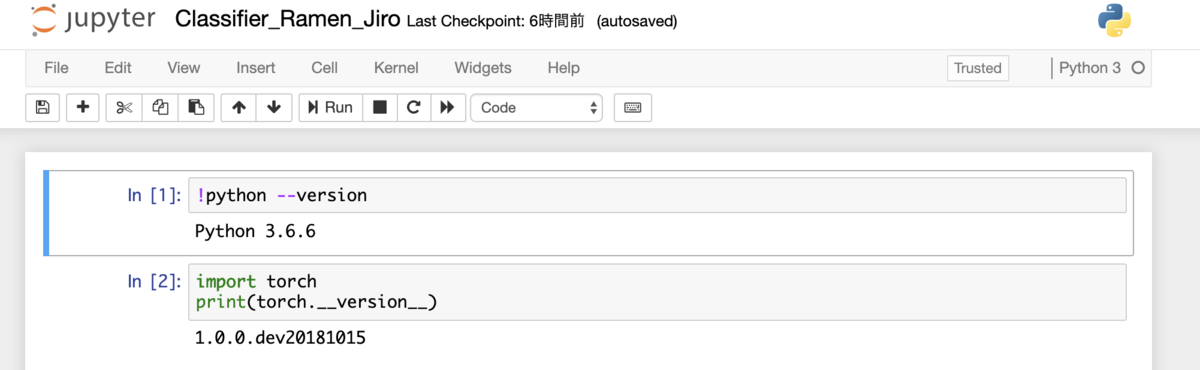
ABEJA PlatformはCloud上でMLOpsのプロセスを実行することが可能、いわゆる機械学習の開発・運用基盤です。ABEJA Platformのアカウントを持っていれば、Consoleという管理画面が使え、その上でjupyter notebookで作業を進めることができます。 https://console.abeja.io アカウントがある方はこちらからログイン後にjupyter notebookを使うことができます。アカウントが無い方は https://abejainc.com/platform/ja/contact/ から問い合わせをお願いいたします。
上の図はABEJA Platform上でjupyter notebookを扱っている例です。尚、以下では各種実行に必要な変数がありますが、Consoleから全て確認ができますので、確認した値をご利用ください。
- organization_id = 'xxxxxxxxx' - user_id = 'user-xxxxxxxxx' - personal_access_token = 'xxxxxxxxx' - channel_id = 'xxxxxxxxx'
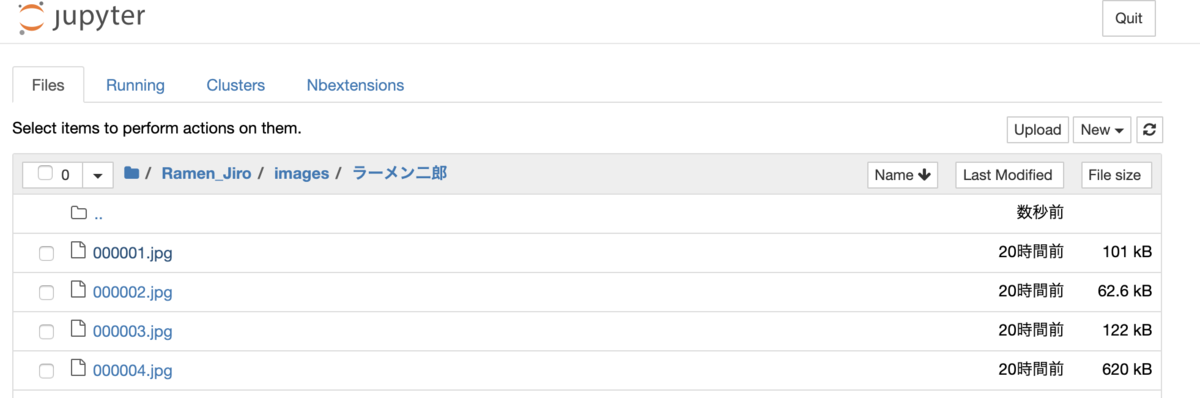
icrawlerで画像を保存
from icrawler.builtin import GoogleImageCrawler # getting crawling data using icralwer # search query queries = [u'ラーメン二郎', u'長崎ちゃんぽん'] for q in queries: print(q) crawler = GoogleImageCrawler(storage = {'root_dir' : 'images/'+q}) crawler.crawl(keyword = q, max_num = 200)
今回はicrawlerを利用してGoogleの検索結果からラーメン二郎と長崎ちゃんぽんの画像を引っ張ってきます。まずはABEJA Platformでのnotebookの作業配下に images/{query} というディレクトリを切って画像を保存します。それぞれ200枚ずつのデータを蓄積します。sample codeは上記のものになります。sample codeを実行すると上図のようにjupyter notebookの作業ディレクトリ配下に画像が保存されます。
学習データのメタ情報をjsonとして作成
import json # create training categories data json_data['categories'] = {} category_data = [] category_data.append({'labels':[], 'category_id':1, 'name':'Ramen'}) labeled_data = [] labeled_data.append({'label_id':1, 'label':'Ramen_jiro'}) labeled_data.append({'label_id':2, 'label':'Nagasaki_Champon'}) labeled_data.append({'label_id':3, 'label':'Other'}) json_data['categories'] = category_data json_data['categories'][0]['labels'] = labeled_data # format is below # {"categories": [{"labels": [{"label_id": 1, "label": "Ramen_jiro"}, {"label_id": 2, "label": "Nagasaki_Champon"}, {"label_id": 3, "label": "Other"}], "category_id": 1, "name": "Ramen"}]} json.dump(json_data, open('categories.json','w'))
学習データを作成するために、icrawlerによって集めた画像が何のラベルを持つべきかの定義を行います。定義としてはlabel_id : 1〜3、それぞれにRamen_jiro、Nagasaki_Champon、Otherという形でラベル名を持ちます。このあとの作業としてABEJA Platform Datalakeに画像を登録しつつ、その画像が何のLabelなのかを一緒に登録します。これでcrawlingした結果をそのまま学習データとして活用する事ができます。もちろん、Datalakeに登録した画像をAnnotationして人の目を通して学習データを手作業で作成することもできます。ただし、ここでは省略。
ABEJA Platform Datalakeへchannelを作成
A Sample tutorial — ABEJA Dataset Library documentation
from abeja.datalake import Client as DatalakeClient from abeja.datalake.storage_type import StorageType # create ABEJA Platform Datalake channel organization_id = 'xxxxxxxxx' user_id = 'user-xxxxxxxxx' personal_access_token = 'xxxxxxxxx' credential = { 'user_id': user_id, 'personal_access_token': personal_access_token } datalake_client = DatalakeClient(organization_id=organization_id, credential=credential) name = 'Ramen_jiro' description = 'a channel for ramen_jiro' channel = datalake_client.channels.create(name, description, StorageType.DATALAKE.value)
収集したラーメン二郎と長崎ちゃんぽんの画像データをABEJA Platform DatalakeというObject Storageに保存します。。まずDatalakeに対しての手順として、1.channelを作成する、2.channelにデータを登録する が必要になります。Datalakeへの操作としてはABEJA Platform SDKがあるので、それを利用すると簡単なpythonコードで操作が可能になります。SDKのドキュメント、チュートリアルは上のURLにあります。上のsample codeを実行するとDatalakeにchannelを作成します。channelはデータソースを定義するために作成します。今回で言うラーメンの画像とラベルデータの保存先となります。
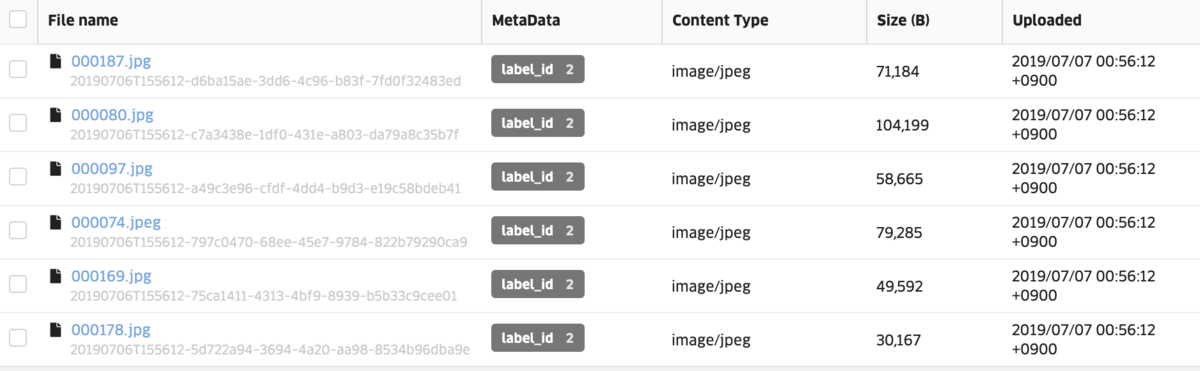
ABEJA Platform Datalakeへ画像を登録
import glob from abeja.datalake import Client as DatalakeClient # upload images client = DatalakeClient() organization_id = 'xxxxxxxxx' channel_id = 'xxxxxxxxx' datalake_client = DatalakeClient(organization_id=organization_id) channel = datalake_client.get_channel(channel_id) queries = [{'name':u'ラーメン二郎', 'label_id':1},{'name':u'長崎ちゃんぽん','label_id':2}] for q in queries: files = glob.glob('images/'+q['name']+'/*') metadata = {'label_id':q['label_id']} for file in files: res = channel.upload_file(file, metadata=metadata)
jupyter notebook上でicrawlerがimages/{query}という形で保存先のディレクトリでデータを切り分けたので、それぞれの画像データと正解データとなるlabel_idをDatalakeに登録します。sample codeは上記のものになります。sample codeを実行すると上図のようにDatalakeのchannelに画像データとlabel_idのデータが閲覧可能になります。
ABEJA Platform Datasetの作成、学習データをimportする
import json from abeja.datasets import Client # create dataset ORGANIZATION_ID = 'xxxxxxxxx' client = Client(organization_id=ORGANIZATION_ID) props = json.load(open('categories.json','r')) dataset = client.datasets.create(name='ramen_jiro_dataset', type='classification', props=props)
Datalakeに登録したデータを学習データとして扱う、目視で確認するためにDatasetという機能を利用します。まずはdatasetを作成します。学習データのメタ情報をjsonとして作成 のパートで保存したcategories.jsonというファイルをここで利用します。
from abeja.datalake import Client as DatalakeClient # get datalake files # import from datalake to dataset client = DatalakeClient() organization_id = 'xxxxxxxxx' channel_id = 'xxxxxxxxx' datalake_client = DatalakeClient(organization_id=organization_id) channel = datalake_client.get_channel(channel_id) for file in channel.list_files(): source_data = [ { 'data_type': file.content_type, 'data_uri': file.uri, } ] attributes = { 'classification': [ { 'category_id': 1, 'label_id': file.metadata['label_id'] } ] } dataset_item = dataset.dataset_items.create(source_data=source_data, attributes=attributes)
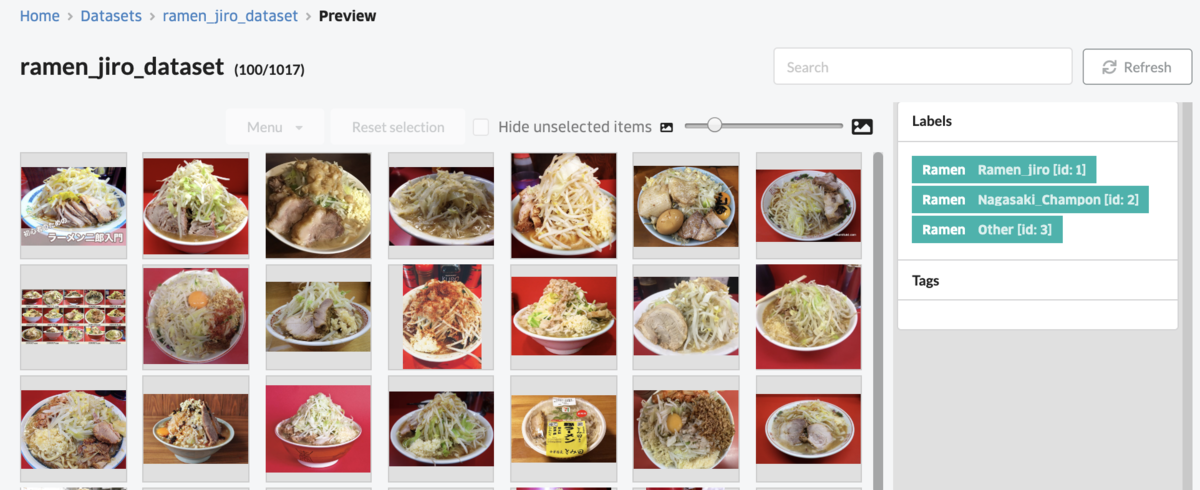
次にDatalakeからDatasetに対象のデータをimportします。上記sample codeを実行するとDatasetの画面から一覧を確認することができます。画面右にあるlabelをクリックするとラーメン二郎、長崎ちゃんぽんのそれぞれのDatasetを見ることができます。
ABEJA PlatformのTemplateを用いて学習、Deployする
Templateの中身については上記githubに詳細が記載されています。 This template uses transfer-learning from VGG16 ImageNet. モデルはVGG16の転移学習によって行われています。
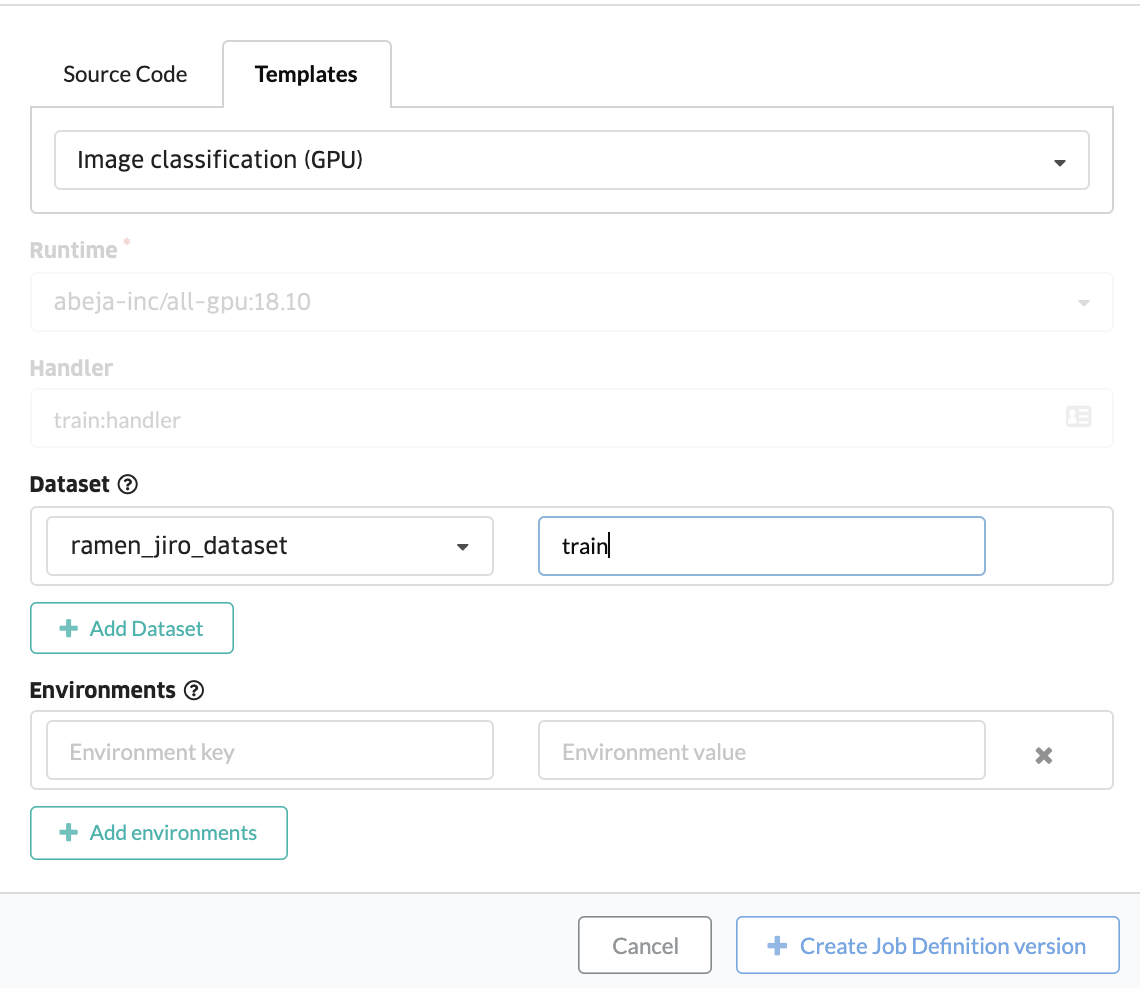
ABEJA PlatformのConsoleを使って、学習のTemplateを利用します。ConsoleのJob Definitionというメニューから学習jobを設定できます。Template機能を使う場合は、表示された画面の中で Templates というタブを選択してください。ソースコードを登録したい場合は Source Code というメニューを選択しますが、今回はSource Codeは使用しません。


続けてtrain jobを作成します。先程登録したTemplateのjobをこちらの画面で登録していきます。上記画面にて項目を選択するだけで実行が可能です。しばらくするとtrain jobが停止し、学習が完了した状態を確認することができます。

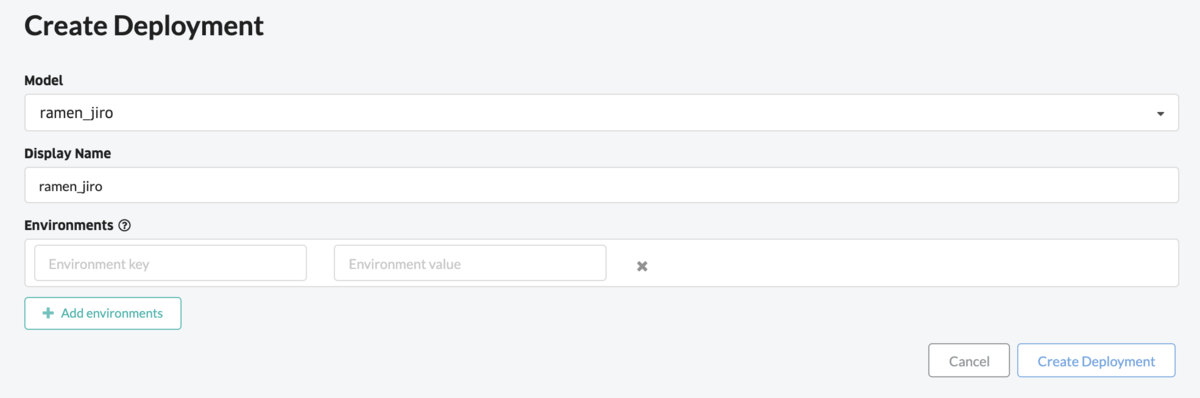
Train jobと同様にDeployについてもノンプログラミングで行います。Deployの機能は作成したモデルを実行できる環境に配置することです。ここではWebAPIとして実行する例を記載していきます。上図ではまずはTrain jobで作成されたモデルを定義しています。作成されたモデルをDeployするための設定も付け加えます。これでモデルを実行できる環境が整いました。
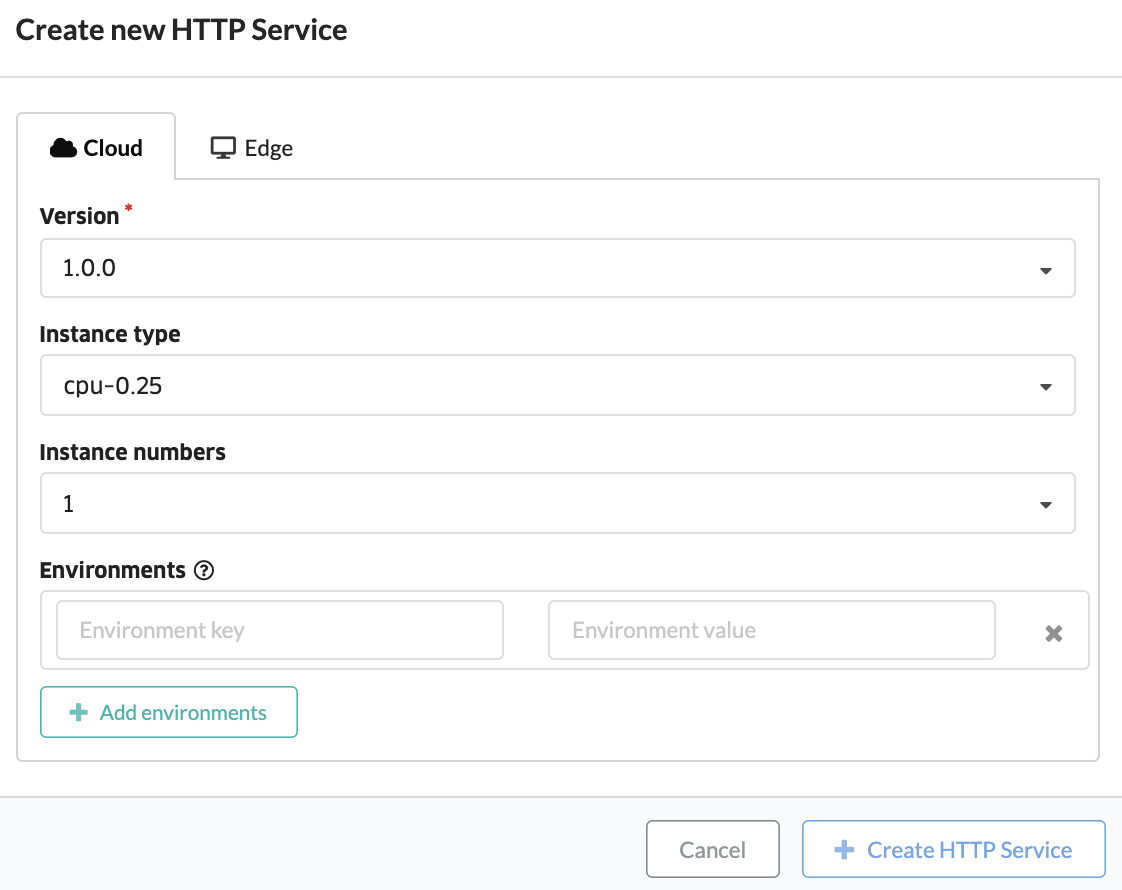
DeployされたモデルをWebAPIとして呼び出すための設定を加えます。Deployの画面で 必要な項目を選択、Create HTTP Service ボタンを押下します。
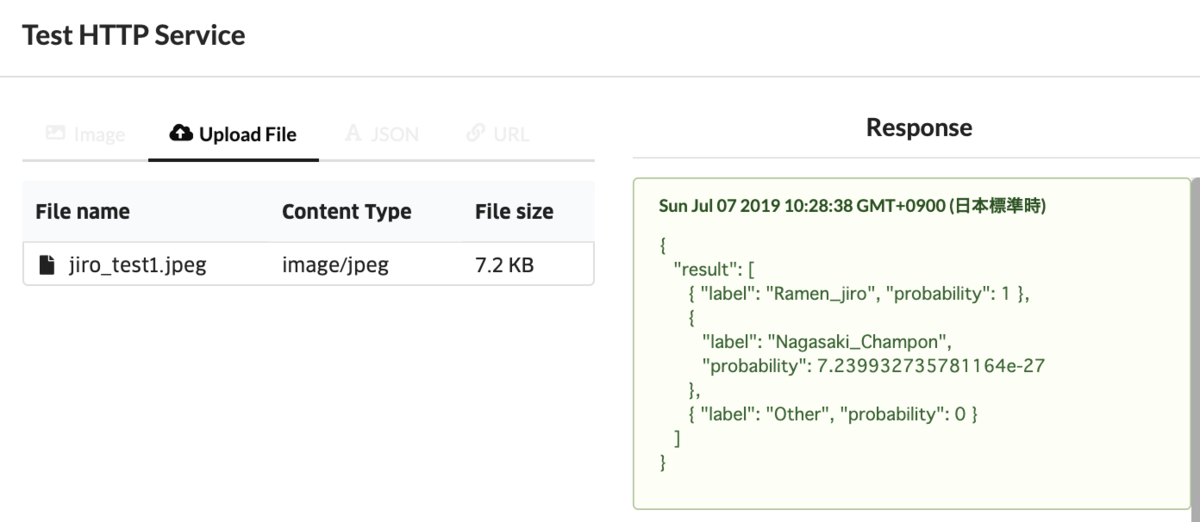
{ "result": [ { "label": "Ramen_jiro", "probability": 1 }, { "label": "Nagasaki_Champon", "probability": 7.239932735781164e-27 }, { "label": "Other", "probability": 0 } ] }
作成されたHTTP Serviceに対してテストを実施してみます。ラーメン二郎の画像をアップロードし、それに対してJSONフォーマットでの結果が返ってくることを確認します。上記のようにRamen_jiroであるProbabilityが1となっているので、100%ラーメン二郎だという回答になっています。あとはHTTP Serviceを外部向けのサービスとして公開するだけです。Deployの画面でAdd Endpoint というボタンを押下すると外部向けのEndpointが作成されるので、作成されたEndpointに対して画像をpostすると上記テストと同じようにJSONフォーマットの結果が返ってきます。
cURL command curl -X POST \ -u user-xxxxxxxxx \ -H "Content-Type: image/jpeg" \ --data-binary @jiro_test1.jpg \ https://abeja-internal.api.abeja.io/deployments/yyyyyyyy
{ "result": [ { "label": "Ramen_jiro", "probability": 1 }, { "label": "Nagasaki_Champon", "probability": 7.239932735781164e-27 }, { "label": "Other", "probability": 0 } ] }
最後に
いかがでしたでしょうか。ABEJA Platform上でjupyter notebook、consoleを使いこなし、更にはモデルのアルゴリズムの中身を知らなくてもノンプログラミングでサービス化までできます。本日の内容は本当に簡単なものを紹介しましたが、これらの機能を利用することで様々なサービスをABEJA Platform上で公開することができます。その他、多くのドキュメントがあるので、是非下記URLを参照してください。